리뷰 Intro
Qwen3이 나온 시점에서 좀 늦긴 했지만, 그래도 Omni 모델이기에 Qwen2.5-Omni Technical Report를 파헤쳐 보고자 한다.
Qwen 계열 자체가 현재 Llama와 같은 오픈소스 모델을 제치고 오픈소스 모델 계열 중에서 가장 높은 평가를 받고 있기에 Qwen의 최신 멀티모달 모델에 대한 매우 중요한 테크 리포트지 않을까 싶다. 사용된 방법론이 상당히 디테일하고 모델 구조 또한 그림과 함께 잘 설명되어 있어서 모델 파악에 많은 도움이 되었다.
결론: 중요도 5/5
github: https://github.com/QwenLM/Qwen2.5-Omni
GitHub - QwenLM/Qwen2.5-Omni: Qwen2.5-Omni is an end-to-end multimodal model by Qwen team at Alibaba Cloud, capable of understan
Qwen2.5-Omni is an end-to-end multimodal model by Qwen team at Alibaba Cloud, capable of understanding text, audio, vision, video, and performing real-time speech generation. - QwenLM/Qwen2.5-Omni
github.com
Abstract
- 이 보고서에서는 텍스트, 이미지, 오디오, 비디오 등 다양한 모달리티를 인식하고, 동시에 텍스트와 자연스러운 음성을 스트리밍 방식으로 생성할 수 있는 end-to-end 멀티모달 모델인 Qwen2.5-Omni를 소개함.
- 멀티모달 정보 입력의 스트리밍 처리를 가능하게 하기 위해, 오디오 및 비주얼 인코더는 block-wise (블록 단위) 처리 방식을 사용. 이 전략은 멀티모달 데이터의 긴 시퀀스를 효율적으로 분리하여 처리하며, 인식 기능은 멀티모달 인코더에 맡기고, 긴 시퀀스의 모델링은 대형 언어 모델이 담당하도록 함. 이러한 역할 분담은 shared attention mechanism (공유 어텐션 메커니즘)을 통해 서로 다른 모달리티 간의 융합을 향상시킴.
- 비디오 입력과 오디오 간의 타임스탬프를 동기화하기 위해, 오디오와 비디오를 번갈아 배치하며, 이를 위한 새로운 위치 임베딩 방식인 TMRoPE(Time-aligned Multimodal RoPE)를 제안함.
- 텍스트와 음성을 동시에 생성하되 상호 간섭을 방지하기 위해 Thinker-Talker 아키텍처를 도입함. 이 프레임워크에서 Thinker는 텍스트 생성을 담당하는 대형 언어 모델이며, Talker는 Thinker의 hidden representation을 직접 활용하여 오디오 토큰을 생성하는 dual-track auto-regressive (양방향 자동 회귀) 모델. Thinker와 Talker는 모두 end-to-end 학습 및 추론이 가능하도록 설계되어 있음.
- 스트리밍 방식으로 오디오 토큰을 디코딩하기 위해, 초기 지연 시간을 줄이기 위해 receptive field를 제한하는 sliding window DiT를 도입함.
- Qwen2.5-Omni는 유사한 규모의 Qwen2.5-VL 모델과 성능이 비슷하며, Qwen2-Audio 모델보다는 뛰어난 성능을 보임. 또한, Qwen2.5-Omni는 Omni-Bench와 같은 멀티모달 벤치마크에서 최신 성능을 기록함.
- 특히, end-to-end speech instruction following에서의 성능은 텍스트 입력을 활용한 경우와 동등한 수준이며, 이는 MMLU 및 GSM8K 등의 벤치마크에서 확인할 수 있음.
- 음성 생성 측면에서도, Qwen2.5-Omni의 스트리밍 Talker는 기존의 스트리밍 및 비스트리밍 모델 대비 높은 강건성과 자연스러움을 보여준다.

1 Introduction
- 일상생활에서 인간은 주변의 시각 및 청각 정보를 동시에 인식할 수 있음. 이러한 정보를 뇌를 통해 처리한 후, 글쓰기, 발화, 도구 사용(및 신체적 행동) 등을 통해 피드백을 표현하며, 세상의 다양한 생명체들과 정보를 주고받고 지능을 발휘함.
- 최근 몇 년간 일반 인공지능의 모습이 점점 더 뚜렷해지고 있으며, 이는 주로 대규모 언어 모델(LLM)의 발전에 기인. 이러한 모델들은 방대한 양의 텍스트 데이터를 기반으로 학습되어, 인간이 생성한 high-level discrete representation (고차원적인 이산 표현)을 기반으로 복잡한 문제를 해결하고 빠르게 학습하는 능력을 보여주고 있음.
- 더 나아가, Language-Audio-Language Models (LALMs)과 Language-Visual-Language Models (LVLMs)의 등장으로, LLM은 end-to-end 방식으로 청각 및 시각 능력을 확장할 수 있게 됨. 그러나 이러한 다양한 모달리티를 end-to-end 방식으로 효율적으로 통합하고, 가능한 많은 데이터를 활용하며, 인간의 의사소통처럼 텍스트와 음성 스트림으로 응답을 제공하는 것은 여전히 큰 도전 과제로 남아 있음. (그냥 multimodal LLM은 어렵다)
- 통합적이고 지능적인 Omni 모델을 개발하기 위해서는 몇 가지 핵심 요소를 신중하게 고려해야 함. 첫째, 텍스트, 이미지, 비디오, 오디오 등 다양한 모달리티를 공동으로 학습시키기 위한 체계적인 방법을 구현하는 것이 중요하며, 이를 통해 모달리티 간 상호 강화가 이루어져야 함. 특히 비디오 콘텐츠의 경우, 오디오와 시각 신호의 시간적 요소를 동기화하는 것이 중요.
- 둘째, 텍스트 및 음성 토큰과 같은 서로 다른 모달리티의 출력 간 간섭을 관리하여, 출력 학습 과정이 서로 방해되지 않도록 해야 함.
- 마지막으로, 멀티모달 정보를 실시간으로 이해하고 오디오 출력을 효율적으로 스트리밍할 수 있는 아키텍처 설계를 탐색하여 초기 지연 시간을 줄일 필요가 있음.
- 이 보고서에서는 Qwen2.5-Omni를 소개. 이 모델은 하나의 통합된 구조로 여러 모달리티를 처리하고, 텍스트와 자연스러운 음성 응답을 스트리밍 형식으로 동시에 생성할 수 있음.
- 첫 번째 과제를 해결하기 위해, 우리는 TMRoPE(Time-aligned Multimodal RoPE)라는 새로운 위치 임베딩 기법을 제안. 이 방식은 오디오와 비디오 프레임을 시간 순서에 따라 번갈아 배치하여 비디오 시퀀스를 효과적으로 표현함.
- 두 번째 과제를 해결하기 위해 Thinker-Talker 아키텍처를 도입. 여기서 Thinker는 텍스트 생성을, Talker는 스트리밍 음성 토큰 생성을 담당. Talker는 Thinker로부터 고차원 표현을 직접 전달받아 사용. 이 설계는 인간이 다양한 신호를 서로 다른 기관으로 생성하면서도 같은 신경망을 통해 이를 동시에 조정하는 방식에서 영감을 얻은 것. Thinker-Talker 아키텍처는 각 구성 요소가 서로 다른 신호를 생성하도록 설계되었으며, 종단형(end-to-end) 방식으로 공동 학습됨.
- 스트리밍과 관련된 과제를 해결하고 멀티모달 신호의 실시간 이해를 위한 prefilling (사전 채우기)를 가능하게 하기 위해, 우리는 모든 멀티모달 인코더에 블록 단위 스트리밍 처리 방식을 적용. 음성의 스트리밍 생성을 지원하기 위해, 음성 토큰을 생성하는 dual-track auto-regressive 모델과 이 토큰들을 파형으로 변환하는 DiT 모델을 함께 도입하여 스트리밍 오디오 생성을 구현하고 초기 지연을 최소화함. 이러한 설계는 모델이 멀티모달 정보를 실시간으로 처리하고 효과적으로 사전 채우기를 수행하여 텍스트와 음성 신호를 동시에 생성할 수 있도록 함.
- Qwen2.5-Omni는 유사한 규모의 Qwen2.5-VL과 비슷한 성능을 보이며, 이미지와 오디오 처리 능력에서는 각각 Qwen2-Audio를 능가. 또한, Qwen2.5-Omni는 OmniBench, AV-Odyssey Bench 등 다양한 멀티모달 벤치마크에서 SOTA를 기록함. 특히, 음성 기반 명령 수행 능력은 텍스트 입력 기반 성능과 유사하며, 이는 MMLU, GSM8K와 같은 벤치마크에서 입증됨. 음성 생성의 경우, Qwen2.5-Omni는 seed-tts-eval에서 test-zh, test-en, test-hard 세트에 대해 각각 1.42%, 2.33%, 6.54%의 WER (word-error-rate)를 기록하며, MaskGCT와 CosyVoice 2를 능가함.
2 Architecture

2.1 Overview
- Qwen2.5-Omni는 Thinker-Talker 아키텍처를 채택하고 있음 (Fig. 2).
- Thinker는 뇌와 같은 역할을 하며, 텍스트, 오디오, 비디오 모달리티로부터 입력을 처리하고 이해하는 기능을 수행하며, 고차원 표현과 이에 대응하는 텍스트를 생성함.
- Talker는 인간의 입처럼 작동하며, Thinker가 생성한 고차원 표현과 텍스트를 스트리밍 방식으로 받아들여 자연스럽게 음성의 이산 토큰을 출력함.
- Thinker는 Transformer 디코더로 구성되며, 정보 추출을 위한 오디오 및 이미지 인코더와 함께 작동. 반면, Talker는 Mini-Omni에서 영감을 받은 dual-track auto-regressive Transformer 디코더 아키텍처로 설계됨.
- 학습과 추론 과정 모두에서, Talker는 Thinker로부터 고차원 표현을 직접 전달받고, Thinker의 전체 과거 문맥 정보도 공유함. 이로 인해 전체 아키텍처는 하나의 통합된 모델로 작동하며, end-to-end 학습 및 추론이 가능함.
2.2 Perceivation
Text, Audio, Image and Video (w/o Audio)
- Thinker는 텍스트, 오디오, 이미지, 오디오가 없는 비디오를 입력받아 이를 hidden representation sequence로 변환하여 처리함. Text tokenizing에는 Qwen의 tokenizer를 사용하며, 이는 byte-level byte-pair encoding (BPE)를 기반으로 하고 151,643개의 일반 토큰을 포함한 어휘 집합을 가짐.
- 오디오 입력과 비디오의 오디오 트랙은 16kHz로 리샘플링한 후, 원시 파형을 128채널 mel-spectogram으로 변환 (window size 25ms, hop size 10ms). 오디오 표현의 각 프레임이 원래 오디오 신호의 약 40ms 구간에 해당하도록, Qwen2-Audio에서 사용된 오디오 인코더를 채택.
- 시각 인코더는 Qwen2.5-VL의 비전 트랜스포머(ViT) 기반 모델을 사용하며, 약 6억 7천 5백만 개의 파라미터를 포함하고 있어 이미지와 비디오 모두를 효과적으로 처리할 수 있음. 이 비전 인코더는 이미지와 비디오 데이터를 혼합하여 학습하는 전략을 통해 이미지 이해와 비디오 인식을 동시에 강화함.
- 오디오 샘플링 속도에 맞추어 비디오 정보를 최대한 보존하기 위해 dynamic frame rate를 적용하여 비디오를 샘플링하며, 일관성을 유지하기 위해 각 이미지는 두 개의 동일한 프레임으로 처리한다.
- (오디오 속도에 맞춰 가까운 비디오 frame을 뽑아옴. 이미지의 경우 하나를 오디오 샘플 개수에 맞춰 뽑아오겠지만 영상처럼 취급하기 위해 그냥 하나 복사해서 2 frame짜리 영상으로 취급. 즉 오디오 sample이 10개일 때 이미지: 복사해서 0, 1 frame [0,0,0,0,0,1,1,1,1,1]로 입력. 비디오 frame이 20개일 경우 [0,2,4,6,8,10,12,14,16,18] frame을 입력)

Video and TMRoPE
- 우리는 오디오와 비디오를 시간 순으로 교차 배열하는 time-interleaving 알고리즘과 함께 새로운 위치 인코딩 방식인 TMRoPE (Time-aligned Multimodal RoPE)를 제안 (Fig. 3).
- TMRoPE는 멀티모달 입력의 3차원 위치 정보를 인코딩하는 방식으로, 기존의 M-RoPE(Multimodal Rotary Position Embedding)에 절대 시간 정보를 결합한 구조. 이를 위해 기존 로터리 임베딩을 시간(temporal), 높이(height), 너비(width) 세 가지 구성 요소로 분해.
- 텍스트 입력의 경우, 세 구성 요소에 동일한 위치 ID를 사용하여 M-RoPE는 사실상 1D-RoPE와 동일하게 동작.
- 오디오 입력도 마찬가지로 동일한 위치 ID를 사용하며, 절대 시간 위치 인코딩을 도입한다. 여기서 하나의 시간 ID는 40ms를 의미.
- 이미지 처리 시, 시각 토큰의 시간 ID는 일정하게 유지되며, 높이와 너비 구성 요소에는 이미지 내 위치에 따라 개별 ID가 부여됨.
- 오디오가 포함된 비디오 입력의 경우, 오디오는 40ms 단위로 동일한 위치 ID로 인코딩되며, 비디오는 시간 ID가 프레임마다 증가하는 일련의 이미지로 처리됨. 높이 및 너비 구성 요소는 이미지와 동일한 방식으로 ID가 부여됨. 비디오의 프레임 속도는 고정되어 있지 않기 때문에, 실제 시간 간격에 따라 프레임 간 시간 ID를 동적으로 조정하여 한 시간 ID가 40ms에 해당하도록 함.
- (기존에 쓰이던 위치 기반 로터리 임베딩을 2개 더 추가해서 최종 합치는 형태. text나 오디오같이 추가할게 없으면 1개를 쓰고 나머지 2개는 고정값으로 통일, 이미지는 2개를 쓰고 1개 (시간축)을 고정값으로 통일. 영상은 3개를 다 쓰는 형태)
- 모델 입력에 여러 모달리티가 포함된 경우, 각 모달리티의 위치 번호는 이전 모달리티의 최대 위치 ID에서 1씩 증가시키며 초기화됨 (모달리티가 바뀌면 다음 순번의 ID로 넘어간다는 얘기). TMRoPE는 위치 정보 모델링을 향상시켜 다양한 모달리티 간 통합을 극대화하고, Qwen2.5-Omni가 여러 모달리티의 정보를 동시에 이해하고 분석할 수 있도록 함.
- 각 모달리티에 위치 정보를 통합한 후, 우리는 표현을 순서대로 배열한다. 모델이 시각 및 청각 정보를 동시에 수신할 수 있도록, Fig. 3에서 보듯 오디오가 포함된 비디오 입력에는 time-interleaving이라는 특별한 설계를 적용하였다. 이 방식은 실제 시간 기준으로 2초 단위로 비디오-오디오 표현을 나눈 후, 해당 구간에서 시각 표현을 앞쪽에, 오디오 표현을 뒤쪽에 배치하여 교차 배열. (그림상에 vision representation이 2개인 이유는 그냥 vision encoder output이 audio encoder output의 두배여서로 추정)
2.3 Genration
Text
- 텍스트는 Thinker에 의해 직접 생성됨. 텍스트 생성 방식은 널리 사용되는 대형 언어 모델(LLM)들과 본질적으로 동일하며, 어휘 분포에 기반한 autoregressive sampling을 통해 텍스트를 생성. 생성 과정에서는 repetition penalty나 top-p 샘플링과 같은 기법이 다양성을 높이기 위해 적용될 수 있음.
Speech
- Talker는 Thinker가 생성한 고차원 표현과 샘플링된 텍스트 토큰의 임베딩을 함께 입력으로 받음. 이처럼 고차원 표현과 이산 샘플 토큰(Thinker가 만들어낸 출력 text)을 함께 사용하는 것은 이 구조에서 핵심적인 요소임.
- 스트리밍 방식의 음성 생성 알고리즘에서는, 전체 텍스트가 완전히 생성되기 전에 콘텐츠의 tone나 attitude를 예측해야 함. Thinker가 제공하는 고차원 표현에는 이러한 정보가 암묵적으로 담겨 있어 보다 자연스러운 스트리밍 생성이 가능함.
- 또한, Thinker의 표현 공간은 음성 유사성보다는 semantic similarity (의미적 유사성)을 주로 반영함. 따라서 발음은 다르지만 의미적으로 유사한 단어들이 매우 비슷한 고차원 표현을 가질 수 있으며, 이러한 불확실성을 제거하기 위해 샘플링된 이산 텍스트 토큰의 입력이 필요함.
- 우리는 효율적인 음성 코덱인 qwen-tts-tokenizer를 설계하였다. 이 토크나이저는 음성의 핵심 정보를 효과적으로 표현하며, causal audio decoder를 통해 스트리밍 방식으로 음성으로 복원될 수 있음.
- Talker는 이 정보를 받은 후 autoregressive 방식으로 음성 토큰과 텍스트 토큰을 생성하기 시작함. 이때 음성 생성은 단어 수준이나 타임스탬프 수준의 정렬을 요구하지 않기 때문에, 학습 데이터와 추론 과정의 요구사항이 크게 간소화됨.
2.4 Design for Streaming
- 스트리밍 오디오 및 비디오 상호작용의 맥락에서, 초기 패킷 지연은 시스템의 스트리밍 성능을 나타내는 중요한 지표. 이 지연 시간은 여러 요인의 영향을 받음.
- 첫째, 멀티모달 정보 입력을 처리하는 데 발생하는 지연,
- 둘째, 첫 번째 텍스트 입력이 수신된 시점부터 첫 번째 음성 토큰이 출력되기까지의 지연,
- 셋째, 첫 음성 구간을 실제 오디오로 변환하는 데 걸리는 시간,
- 넷째, 모델 크기나 연산량(FLOPs) 등과 관련된 아키텍처 고유의 지연.
- 이 논문에서는 이러한 네 가지 측면에서 지연 시간을 줄이기 위해 적용된 알고리즘적 및 아키텍처적 개선 사항들을 후속해서 다룸.
Support Prefilling
- chunked-prefills는 현대 추론 프레임워크에서 널리 사용되는 메커니즘. 이를 멀티모달 상호작용에 적용하기 위해, 우리는 오디오 및 비전 인코더를 시간 축을 따라 블록 단위 어텐션을 지원하도록 수정함.
- 구체적으로, 오디오 인코더는 전체 오디오에 대한 전역 어텐션 방식에서 2초 단위 블록마다 어텐션을 수행하는 방식으로 변경됨. (어텐션을 잘라서 작게작게 하겠다)
- 비전 인코더는 효율적인 학습 및 추론을 위해 flash attention을 사용하며, 인접한 2×2 토큰을 하나의 토큰으로 병합하는 간단한 MLP 레이어를 포함함. 패치 크기는 14로 설정되어 다양한 해상도의 이미지를 하나의 시퀀스로 패킹할 수 있도록 함.

Streaming Codec Generation
- 특히 긴 시퀀스에 대한 오디오 스트리밍 생성을 지원하기 위해, 우리는 현재 토큰이 제한된 문맥만을 참조하도록 하는 sliding window block attention mechanism을 제안함. 이를 위해 Flow-Matching 기반 DiT 모델 (Diffusion Transformer)을 사용함. 입력 코드는 Flow-Matching을 통해 mel-spectrogram으로 변환되며, 이후 수정된 BigVGAN을 통해 해당 mel-spectrogram이 실제 음파로 복원됨.
- 코드 (Talker가 생성한 음성 토큰)로부터 음파를 생성하기 위해 인접한 코드들을 블록 단위로 묶고, 이 블록들을 어텐션 마스크로 사용함 (Fig. 4). DiT의 수용 범위는 총 4개의 블록으로 제한되며, 그 안에는 2개의 이전 블록과 1개의 이후 블록이 포함됨. 디코딩 과정에서는 Flow-Matching을 사용해 mel-spectrogram을 청크 단위로 생성하며, 각 코드 청크는 필요한 문맥 블록들에 접근할 수 있도록 함.
- 이 방식은 문맥 정보를 유지함으로써 스트리밍 출력의 품질을 향상시킴. 우리는 또한 BigVGAN의 고정된 수용 범위에도 이 청크 단위 방식을 적용하여 스트리밍 형태의 음파 생성을 가능하게 함.
- (코드 생성은 일반적으로 Talker가 진행. 생성된 코드를 streaming 관점에서 빠르게 음성으로 변환하기 위해 sliding window block attention mechanism을 적용하겠다는 얘기인 것으로 보임. 내용과는 무관한 음성 변환의 속도 관점)
3 Pre-training
- Qwen2.5-Omni는 세 단계의 학습 과정으로 구성됨.
- 첫 번째 단계에서는 LLM의 파라미터를 고정하고, 시각 인코더와 오디오 인코더의 학습에 집중함. 이 단계에서는 대규모의 오디오-텍스트 및 이미지-텍스트 쌍 데이터를 활용하여 LLM 내부에서 의미적 이해를 강화함.
- 두 번째 단계에서는 모든 파라미터를 풀고 더 다양한 멀티모달 데이터를 활용해 보다 포괄적인 학습을 진행함.
- 마지막 단계에서는 최대 시퀀스 길이 32k의 데이터를 사용하여 복잡한 장문의 데이터를 이해하는 능력을 향상시킴.
- 모델은 이미지-텍스트, 비디오-텍스트, 비디오-오디오, 오디오-텍스트, 일반 텍스트 등 다양한 유형을 포함하는 다채로운 데이터셋으로 사전 학습됨. Qwen2-Audio에서 제안한 방식에 따라, 계층적 태그를 자연어 프롬프트로 대체하여 일반화 능력과 지시 수행 능력을 향상시킴. (<question>, </question>과 같이 태그를 붙이는 방식보다 '질문: '이나 일반 질문형 프롬프트처럼 자연스러운 말로 입력함. 태그를 붙여 학습시키는 경우 일반화 능력이 떨어진다고 보는 것)
- 초기 사전 학습 단계에서 Qwen2.5-Omni의 LLM 구성 요소는 Qwen2.5의 파라미터로 초기화되며, 시각 인코더는 Qwen2.5-VL과 동일하고, 오디오 인코더는 Whisper-large-v3로 초기화됨. 두 인코더는 고정된 LLM 위에서 별도로 학습되며, 처음에는 각 인코더에 연결된 어댑터 학습을 먼저 수행한 뒤 인코더 자체를 학습함. 이러한 기초 학습 과정은 시각-텍스트 및 오디오-텍스트 간의 핵심적인 의미 정렬 및 연관성을 모델이 잘 이해할 수 있도록 도움.
- 두 번째 학습 단계에서는 이미지 및 비디오 관련 데이터 8천억 토큰, 오디오 관련 데이터 3천억 토큰, 오디오가 포함된 비디오 데이터 1천억 토큰이 추가되며, 이로 인해 멀티모달 학습량과 과제의 다양성이 크게 증가함. 이 단계에서는 청각, 시각, 언어 정보 간의 상호작용과 깊은 이해가 강화되며, 복잡한 현실 세계의 데이터를 다룰 수 있는 능력을 기르는 데 핵심적인 역할을 함. 순수 텍스트 데이터 또한 언어 능력 유지 및 향상에 필수적인 요소로 작용함.
- 학습 효율을 높이기 위해 이전 단계에서는 최대 토큰 길이를 8192로 제한함. 이후 긴 오디오와 비디오 데이터를 포함한 학습에서는 텍스트, 오디오, 이미지, 비디오 데이터를 모두 최대 32,768 토큰까지 확장하여 학습을 진행함. 실험 결과, 이러한 장문 시퀀스 학습 데이터는 모델의 긴 입력 처리 능력을 크게 향상시키는 것으로 나타남.
4 Post-training
4.1 Data Format

4.2 Thinker
- 후속 학습 단계에서는 instruction finetuning을 위해 ChatML(OpenAI, 2022) 형식의 instruction following 데이터를 사용함. 우리가 사용하는 데이터셋은 순수 텍스트 기반 대화 데이터, 시각 모달리티 대화 데이터, 오디오 모달리티 대화 데이터, 그리고 복합 모달리티 대화 데이터를 포함.
4.3 Talker
- Qwen2.5-Omni가 텍스트와 음성 응답을 동시에 생성할 수 있도록 하기 위해 Talker에 대해 세 단계의 학습 과정을 도입함.
- 첫 번째 단계에서는 문맥 연속성을 학습하도록 Talker를 훈련함. (입력으로부터 출력 음성 토큰을 예측하는 일반적 학습을 의미하는 듯)
- 두 번째 단계에서는 DPO를 활용하여 음성 생성의 안정성을 향상시킴.
- 세 번째 단계에서는 다화자 지시문 미세조정을 적용하여 음성 응답의 자연스러움과 제어 가능성을 높임.
- In-Context Learning 학습 단계에서는 Thinker의 텍스트 감독 방식과 유사한 텍스트 기반 감독 외에도, 다음 토큰 예측을 통해 음성 연속 생성 과제를 수행하며, 멀티모달 맥락과 음성 응답이 포함된 대규모 대화 데이터셋을 활용함. 이를 통해 Talker는 의미 표현에서 음성으로의 단조 매핑을 학습하고, 문맥에 적절한 운율, 감정, 억양 등 다양한 속성을 반영해 음성을 표현하는 능력을 습득함. 또한, 특정 목소리가 드문 텍스트 패턴과 연관되지 않도록 하기 위해 timbre disentanglement (음색 분리) 기법도 함께 적용함.
$$\mathcal{L}_{\text{DPO}}(\mathcal{P}_\theta; \mathcal{P}_{\text{ref}}) = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma \left( \beta \log \frac{\mathcal{P}_\theta(y_w \mid x)}{\mathcal{P}_{\text{ref}}(y_w \mid x)} - \beta \log \frac{\mathcal{P}_\theta(y_l \mid x)}{\mathcal{P}_{\text{ref}}(y_l \mid x)} \right) \right]$$
- 화자와 상황의 범위를 넓히기 위해 사전학습 데이터에는 필연적으로 라벨 노이즈와 발음 오류가 포함되며, 이는 모델의 hallucination을 유발할 수 있음.
- 이러한 문제를 완화하기 위해, 우리는 음성 생성의 안정성을 향상시키기 위한 강화 학습 단계를 도입함. 구체적으로, 각 요청 및 응답 텍스트와 참조 음성이 짝지어진 데이터에 대해, 입력 시퀀스 $x$ (입력 텍스트 포함), good and bad generated speech sequence $y_w$, $y_l$로 이루어진 triplet data로 구성된 데이터셋 $\mathcal{D}$를 구축. 이 샘플들은 WER과 punctuation pause error rate을 기반으로 계산된 보상 점수에 따라 순위를 매김. (출력에 대해 stt를 한다는 얘기인듯)
- 마지막으로, 앞서 학습된 기본 모델을 기반으로 화자 특화 미세조정을 수행하여, Talker가 특정 음성을 채택할 수 있도록 하고 음성의 자연스러움을 개선함.
5 Evaluation
- Qwen2.5-Omni에 대한 포괄적 평가를 진행. 모델은 두개의 메인 카테기로라 나뉘어 평가: understanding (X→Text), speech generation (X→Speech)
5.1 Evaluation of X→Text
Text$\rightarrow$Text: 일반적인 평가, 수학 및 과학 능력, 그리고 코딩 능력에 초점을 맞춰 평가
- 일반 평가: MMLU-Pro, MMLU-redux, Livebench0803
- 수학 및 과학 능력 평가: GPQA, GSM8K, MATH
- 코딩 능력 평가: HumanEval, MBPP, MultiPL-E, LiveCodeBench 2305-2409
Audio$\rightarrow$Text: 오디오 이해, 오디오 추론, 음성 채팅과 관련된 평가가 포함
- 오디오 이해: Automatic Speech Recognition (ASR), Speech-to-Text Translation (S2TT), Speech Entity Recognition (SER), Vocal Sound classification (VSC), 음악 등 다양한 오디오 이해 과제에서 성능을 종합적으로 평가
- 오디오 추론: MMAU
- 음성 채팅: VoiceBench와 자체 구축한 음성 지시 벤치마크를 활용
Image$\rightarrow$Text: 대학 수준 문제, 수학, 일반 시각 질의응답, OCR 관련 과제에서의 성능을 평가
- 대학 수준 문제 평가: MMMU와 MMMU-Pro
- 수학 과제: MathVista와 MathVision
- 일반적인 시각 질의응답 과제: MMBench-V1.1, MMVet, MMStar, MME, MuirBench, CRPE, RealWorldQA, MMERealWorld, MM-MT-Bench
- OCR 과제: AI2D, TextVQA, DocVQA, ChartQA, OCRBench_v2
- Referring Expression Comprehension (지시 표현 이해), Object Detection in the Wild (자연 환경 속 객체 탐지), 그리고 자체 구축한 포인트 지정 벤치마크 등을 통해 visual grounding (시각적 결합) 능력도 평가.
Video (w/o Audio)$\rightarrow$Text: Video-MME, MVBench, EgoSchema
Multimodality$\rightarrow$Text: OmniBench
5.1.1 Performance of Text$\rightarrow$Text

- Qwen2.5-Omni를 유사한 규모의 최신 대형 언어 모델(7B)들과 비교. Qwen2.5-Omni의 성능은 일반적으로 Qwen2-7B와 Qwen2.5-7B 사이에 위치 (Table 1). Qwen2.5-Omni는 MMLU-Pro, MMLU-redux, MATH, GSM8K, MBPP, MultiPL-E, LiveCodeBench 등 대부분의 벤치마크에서 Qwen2-7B보다 우수한 성능을 보이며,Text$\rightarrow$Text 과제에서 뛰어난 능력을 입증.
5.1.2 Performance of Audio$\rightarrow$Text


- Qwen2.5-Omni를 다양한 오디오 이해, 오디오 추론, 음성 채팅 벤치마크에서 기존의 대표적인 특화 모델 및 범용 모델들과 비교. Table 2와 3에서 볼 수 있듯이, Qwen2.5-Omni는 오디오 이해 과제에서 다른 최신 방법들보다 우수하거나 유사한 성능을 보여줌.
- 예를 들어, Fleurs_zh, CommonVoice_en, CommonVoice_zh, CoVoST2_en-de, CoVoST2_zh-en 테스트 세트에서 ASR 및 S2TT 성능이 뛰어나며, Whisper-large-v3, Qwen2Audio, MinMo 및 기타 Omni 모델 등 기존의 최첨단 모델들을 능가함. 또한, 음악 및 VSC와 같은 일반적인 오디오 이해 과제에서도 Qwen2.5-Omni는 최고 성능을 기록함.
- Qwen2.5-Omni는 오디오 추론에서도 MMAU 벤치마크의 소리, 음악, 음성 하위 과제에서 우수한 성능을 보여주며, 최고 수준의 결과를 달성함. 이는 Qwen2.5-Omni가 전반적인 오디오 이해 및 추론 능력에서 강력한 성능을 보유하고 있음을 입증함.
- 또한, VoiceBench 평가에서 Qwen2.5-Omni는 평균 점수 74.12점을 기록하며 유사한 크기의 다른 오디오 언어 모델 및 옴니 모델들을 능가함. 이는 음성 상호작용 분야에서 우리 모델의 강력한 역량을 보여줌.
- 다양한 음성 상호작용 성능을 더 깊이 탐색하기 위해, 여러 텍스트 전용 벤치마크의 지시문을 음성으로 변환한 후, Qwen2.5-Omni, Qwen2-Audio, Qwen2-7B를 내부 음성 채팅 벤치마크에서 평가함. 전체 텍스트 지시문의 약 90%가 사용되었으며, Qwen2.5-Omni와 Qwen2-Audio에는 음성 지시문이, Qwen2-7B에는 텍스트 지시문이 주어짐. 표 4에서 볼 수 있듯이, Qwen2.5-Omni는 Qwen2-Audio보다 Qwen2-7B와의 성능 차이를 현저히 좁혔으며, 이는 음성을 활용한 종단 간 상호작용 능력이 크게 향상되었음을 보여줌.

5.1.3 Performance of Image$\rightarrow$Text

- Image$\rightarrow$Text 과제에서의 모델 성능을 종합적으로 평가하기 위해, 우리는 Qwen2.5-Omni를 최신 비전 언어 모델인 Qwen2.5-VL-7B 및 기타 성능이 뛰어난 옴니 모델들과 비교함.
- Table 5에서 볼 수 있듯이, Qwen2.5-Omni는 Qwen2.5-VL-7B와 유사한 성능을 보이며, MMMU, MathVision, MMBench-V1.1-EN, TextVQA, DocVQA, ChartQA 등 여러 벤치마크에서 다른 공개된 옴니 모델들보다 우수한 결과를 달성함. 또한, 대부분의 벤치마크에서 GPT4o-mini를 능가하는 성능을 보임. 이러한 결과는 이미지 이해 분야에서 Qwen2.5-Omni의 뛰어난 역량을 잘 보여줌.
- visual grounding 과제에서 우리는 Qwen2.5-Omni를 Qwen2.5-VL-7B 및 Gemini, Grounding-DINO를 포함한 주요 LVLM들과 비교함. 우리 모델은 box-grounding부터 point-grounding까지 대부분의 벤치마크에서 다른 모델들을 능가하며, 오픈 보캐뷸러리 객체 탐지 과제에서는 42.2mAP라는 우수한 성능을 달성함 (Table 6). 이는 우리 모델의 강력한 시각적 결합 능력을 보여줌.

5.1.4 Performance of Video (w/o Audio)$\rightarrow$Text

- Image$\rightarrow$Text 과제와 유사하게, 우리는 Qwen2.5-Omni를 Qwen2.5-VL-7B 및 기타 옴니 모델들과 비교함. Qwen2.5-Omni는 모든 최신 공개 옴니 모델들과 GPT-4o-Mini를 능가하며, Qwen2.5-VL-7B와 비교해서도 더 우수하거나 경쟁력 있는 성능을 보여주어 비디오 이해 분야에서의 뛰어난 성능을 입증함 (Table 7).
5.1.5 Performance of Multimodality$\rightarrow$Text

- Qwen2.5-Omni는 OmniBench에서 최고 수준의 성능을 기록하였으며, 다른 옴니 모델들을 큰 폭으로 앞섬 (Table 8). 이는 멀티모달 이해 능력에서 우리 모델의 우수성을 보여줌.
5.2 Evaluation of X$\rightarrow$Speech
- Qwen2.5-Omni의 음성 생성 능력을 평가. 관련된 평가 지표가 부족하기 때문에, 본 음성 생성 평가는 주로 텍스트 기반 음성 생성의 TTS 유사성 측면에서 Zero-shot 및 단일 화자 음성 생성 능력의 두 가지 측면에 초점을 맞춤.
- Zero-Shot 음성 생성: SEED 데이터셋을 기반으로, 제로샷 음성 생성에서의 내용 일관성(WER)과 화자 유사도(SIM)를 평가.
- 단일 화자 음성 생성: 화자 미세조정이 적용된 모델의 안정성을 SEED 데이터셋에서 평가하고, 자체 제작한 데이터셋을 활용하여 생성된 음성의 주관적 자연스러움(NMOS)을 평가.
5.2.1 Evaluation of Zero-Shot Speech Generation

- 우리는 Qwen2.5-Omni를 최신 zero-shot TTS 시스템들과 비교함. Qwen2.5-Omni는 매우 경쟁력 있는 성능을 보여주며, In-context learning을 통해 개발된 강력한 음성 이해 및 생성 능력을 강조함 (Table 9). 또한, 강화학습(RL) 최적화 이후, Qwen2.5-Omni는 생성 안정성에서 큰 향상을 보였으며, attention 불일치, 발음 오류, 부적절한 일시 정지 등에서 특히 어려운 테스트 세트인 test-hard에서 뚜렷한 감소를 나타냄.
5.2.2 Evaluation of Single-Speaker Speech Generation
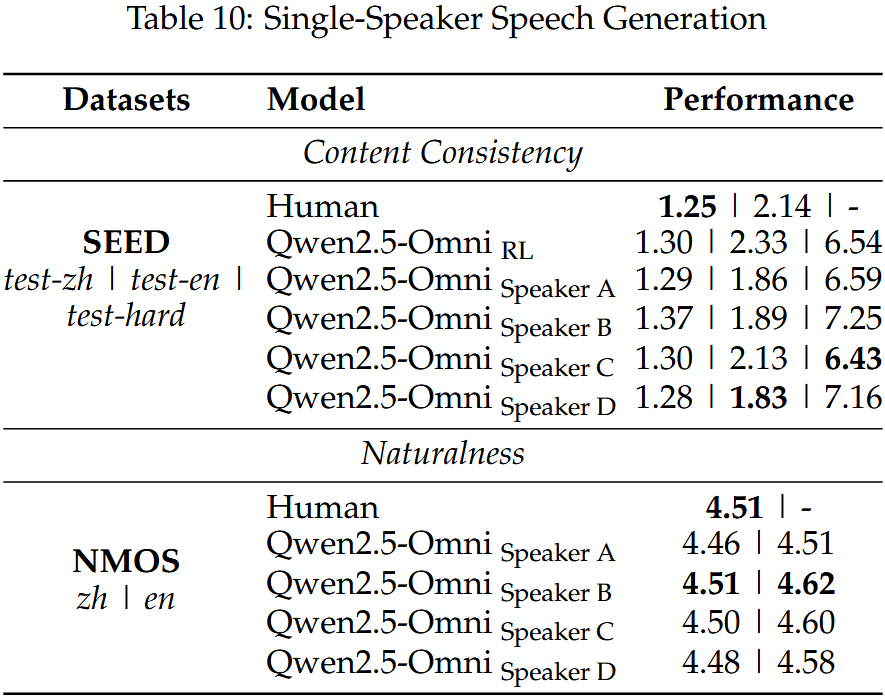
- 우리는 Qwen2.5-Omni 모델의 화자 미세조정 전후 성능과 실제 인간 음성 녹음과의 비교도 수행함. 화자 미세조정이 적용된 Qwen2.5-Omni는 목표 화자의 미묘한 운율 스타일을 보다 정밀하게 반영하면서도, 기반 모델이 제공하는 안정성을 유지하였고, 주관적 및 객관적 지표 모두에서 인간 수준에 근접한 성능을 달성함 (Table 10).
6 Conclusion
- Qwen2.5-Omni는 텍스트와 실시간 음성을 포함한 다양한 모달리티를 이해하고 생성할 수 있도록 설계된 통합 모델임.
- 비디오 통합 기능을 강화하기 위해, 오디오와 비디오의 타이밍을 정렬하는 새로운 위치 임베딩 방식인 TMRoPE를 도입함.
- Thinker-Talker 프레임워크는 서로 다른 모달리티 간의 간섭을 최소화하면서 실시간 음성 생성을 지원함. 또한, 오디오 및 비전 인코딩에 블록 단위 처리를 적용하고, 코드-음파 변환을 위한 슬라이딩 윈도우 메커니즘과 같은 기법을 활용함.
- 이 혁신적인 모델은 복잡한 오디오-비주얼 상호작용과 감정적 맥락이 포함된 음성 대화에서도 뛰어난 성능을 보임. 종합적인 평가 결과, Qwen2.5-Omni는 유사한 크기의 단일 모달리티 모델들을 능가하며, 특히 음성 명령 수행에서 우수한 성능을 보였고, 멀티모달 과제에서도 최고 수준의 성능을 달성함.
- 모델 개발 과정에서 우리는 기존 학계 연구에서 자주 간과되었던 비디오 OCR, 오디오-비디오 협력 이해와 같은 몇 가지 중요한 문제를 확인함.
- 이러한 과제를 해결하기 위해서는 포괄적인 평가 벤치마크와 연구용 데이터셋 구축을 위한 학계와 산업계 간의 협력이 필요함.
- 우리는 Qwen2.5-Omni가 범용 인공지능(AGI)을 향한 중요한 진전을 나타낸다고 믿음. 앞으로는 이미지, 비디오, 음악 등 다양한 모달리티에 걸쳐 출력 능력을 확장하고, 보다 강력하고 빠른 모델을 개발하는 것을 목표로 하고 있음.